通过竞品广告报告搭建词库
运营中必要的插件经过了极致的数据处理,已经十分全面精准。而对于追求推品成功率的单干卖家和部分精品公司,竞品广告报告也是提高推品成功率的不二之选。
本文架构:
- 竞品广告报告的选择方法
- 竞品广告报告处理的底层逻辑
- 竞品广告报告的处理与实操
- 插件与相关网站的使用场景
一、竞品广告报告的选择
- 首先,为什么不用商机探测器计算转化率?因为商机探测器计算出的转化率是过去360天内,这个关键词下所有产品的平均转化率。
- 我做的类目不是很红海的类目,因此,多数产品,我会选择2个与自己产品在外观、功能、属性、价格区间、目标人群最相似、且在bsr上的竞品买广告报告;再选择1个与自己产品最相似,且在nr上的竞品买广告报告。如果认为nr1的水平大概不如自己,我会选择3个与自己产品最相似、且在bsr上的竞品买广告报告。
- 如果是红海,建议买4-5份。为什么选3-5个竞品:数据量越大,偏差越小3-5个竞品是多数人在广告报告价格接受范围内,可参考性较强的数量。下文提到的竞品广告报告,默认和自己后台下载的search term搜索词报告长得一样。
二、竞品广告报告处理的底层逻辑
很多时候,人们在思考的时候相信直觉,相信自己的经验并做出判断。但很多时候,这些经验可能是错误的。因此,我会给出直接并有说服力的论证,证明用竞品广告报告的有效性,与处理数据的有效性;而不仅仅停留在"显而易见,我认为"、"通过直觉,我觉得"、"通过以往经验,我相信"。
- 首先,论证为什么选择竞品的搜索词报告对自己有用、有指导意义,但头部非标的广告报告对非标的借鉴意义有限。
引入一个概率统计/机器学习的概念,叫做"泛化误差(Generalization Error)"。泛化误差测量"一个模型对先前未知数据的预测准确程度",具体的公式为: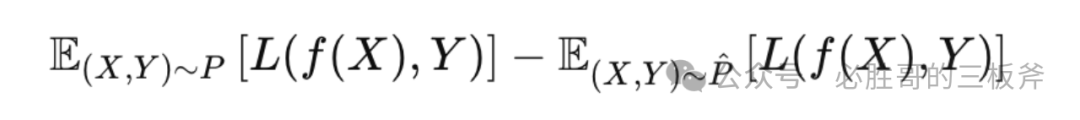 这里,P指被预测数据的真实分布,p̂指已有数据(训练数据)的分布,L是损失函数,用来衡量预测值与真实值的不一样程度,f指这个模型。
这里,P指被预测数据的真实分布,p̂指已有数据(训练数据)的分布,L是损失函数,用来衡量预测值与真实值的不一样程度,f指这个模型。
在亚马逊运营中运用泛化误差的概念,现在我们需要找到一个模型,通过已有数据,去预测我自己产品的cvr和acos。我们需要让p̂(已有数据的分布)尽量接近P(被预测数据的分布),才可以让泛化误差越小,即让预测的准确程度越高。这就是为什么我们需要挑所处阶段、流量结构、外观、功能、属性、价格区间、目标人群最相似的竞品作为数据进行我们的预测——因为最相似产品的数据(已有数据分布p̂),和我们产品的数据(被预测数据的分布P)最接近,所以可以降低泛化误差,因此可以提高预测的准确度。
- 论证为什么新品榜的竞品搜索词报告有充足的借鉴意义,且季节性产品的借鉴意义有限。
引入一个统计学概念,叫做"时间序列分析(time series analysis)",意思是"将原来的销售分解为几部分来看——趋势、周期、时期和不稳定因素,然后综合这些因素,提出销售预测。"建立公式:
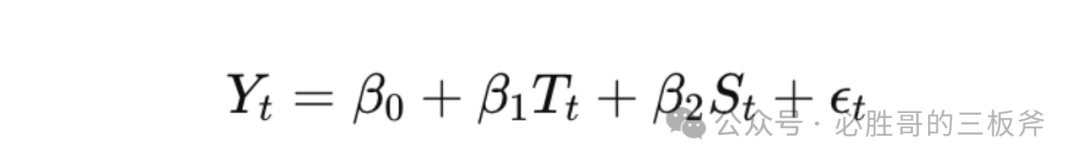
Yt指在预测的时期t的转化率,Tt为通过历史数据预测的时期t的趋势,St为通过历史数据预测的时期t的季节性/周期,ϵt为不稳定因素。
挨个分解来看。ϵt是无法干涉/预测的因素,所以只能抛开不看。由于新品的趋势Ttnew比老品的Ttold更能反映当下的趋势,整体的Ytnew会比整体的Ytold更精准,即新品搜索词报告展现的转化率,在其他条件保持不变的情况下,比老品更可以反映自己即将上架的品的转化率。
通过时间序列分析的公式,我们还可以看到影响预测值Yt的因素还有St,即季节性/周期性。当产品是非季节性产品时,这一项是0;如果是季节性产品,这一项不为0,导致预测转化率Yt的波动会非常大。因此,竞品的搜索词报告对自己即将上架的产品是否有足够借鉴意义,和该品是否具有周期性高度相关。
- 论证为什么bs的竞品搜索词报告有充足的借鉴意义。
引入一个统计学定理,叫做"大数定理(Law of Large Numbers)"。该定理意味着"随着样本大小的增加,样本均值将收敛于总体均值。"套到亚马逊的竞品搜索词报告上,建立公式:
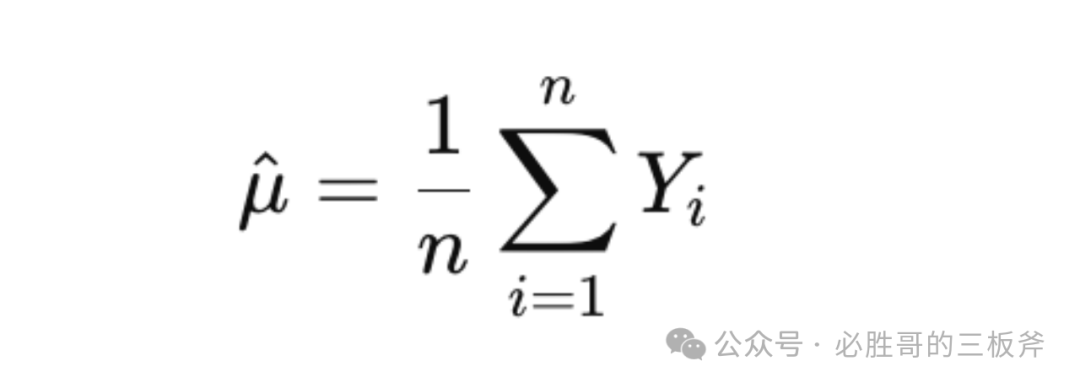
同样,拿转化率cvr举例。在这里,μ^指自己在一个搜索词下的预期转化率,Yi指每一个竞品在这个搜索词下的转化率,n是竞品/竞品搜索词报告数量。通过公式,我们可以得出,随着n(竞品搜索词报告)数量的增加,μ^可以成为真实总体转化率μ的更准确估计。但,由于新品榜的产品数量有限,所以选择去bs榜单获得更多数据,即增加n的值,从而更准确的预估自己的转化率。
不仅是cvr,acos、cpc、ctr等数值,都可以通过增加样本数量(竞品搜索词报告数量)去提高预测数值的准确度。
- 论证为什么取每个搜索词的平均cvr,是代表自己在这个搜索词下最有可能的cvr。
说实话,取平均值,是所有不完美的方法中最有效的一个;最有效的方法是不存在的。我们可以使用排除法去论证这个观点。但是,此方法仅适用于非季节性产品(降低趋势带来的影响),和被买搜索词报告的竞品在各个维度上与自己的产品极为相似(降低数据噪音,noise)的情况。
1)时间序列分析——ARIMA(自回归整合滑动平均模型)、Exponential Smoothing(ETS,指数平滑法)、Exponential Moving Average(EMA,指数移动平均线)
ARIMA自回归整合滑动平均模型的公式为:
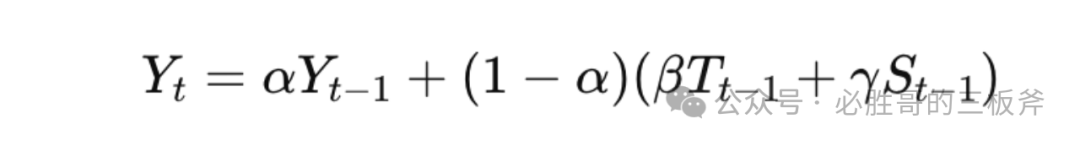
Exponential Smoothing(ETS,指数平滑法)的公式为:
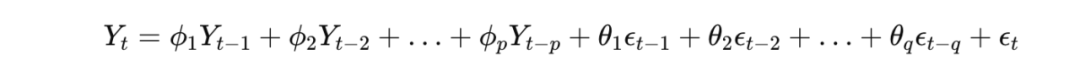
Exponential Moving Average(EMA,指数移动平均线)的公式为:
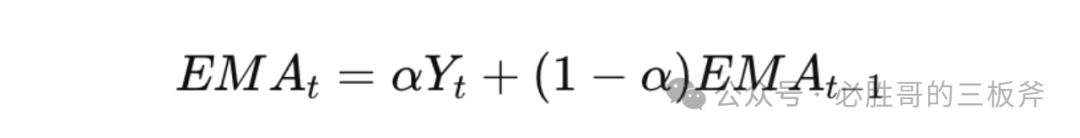
细心的读者可能会发现,两个公式都出现了一个字母:t。t意味着单个的时间点。但是,我们可以买到的搜索词报告涵盖着近两个月的整体数据,而非像第一天、第二天…或第一周、第二周…的时间点的数据,所以任何时间序列分析的模型都行不通。原因很简单,因为咱们只有一个t,即过去两个月。
2) 接下来,我们用简单移动平均线——Simple Moving Average(SMA)去证明"取每个搜索词的平均cvr,是预测自己在这个搜索词下比较可能的cvr"。
依旧拿cvr举例。假设我们买了3个竞品的搜索词报告。针对每一个客户搜索词,3个搜索词报告中单独每一天的cvr分别为Y1,t, Y2,t, Y3,t, t是1,2,…,60,代表近2个月的60天。例如,当t=3时,Y1,3是第一个竞品在第3天的cvr。
这三个竞品在过去2个月的SMA可以被计算为:

这三个竞品的整体SMA可以被计算为:
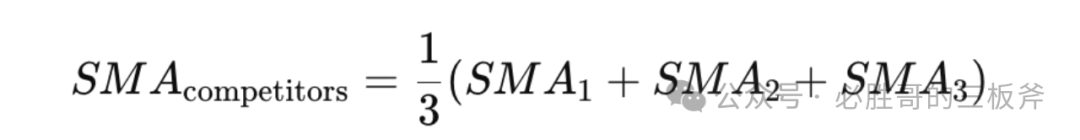
</a> <a href='https://www.goluckyvip.com/news/376429.html'>Tiktok玩家第208篇:怎么提高和达人沟通的效果,话术有什么特点吗?</a> <a href='https://www.kjdsnews.com/a/1960127.html'>通过竞品广告报告搭建词库</a>
<div style='clear: both;'></div>
</div>
<div class='post-footer'>
<div class='post-footer-line post-footer-line-1'>
<span class='post-author vcard'>
发帖者
<span class='fn' itemprop='author' itemscope='itemscope' itemtype='http://schema.org/Person'>
<meta content='https://www.blogger.com/profile/06070620091046206113' itemprop='url'/>
<a class='g-profile' href='https://www.blogger.com/profile/06070620091046206113' rel='author' title='author profile'>
<span itemprop='name'>星空新闻</span>
</a>
</span>
</span>
<span class='post-timestamp'>
时间:
<meta content='https://www21usbcom.blogspot.com/2024/10/blog-post_98.html' itemprop='url'/>
<a class='timestamp-link' href='https://www21usbcom.blogspot.com/2024/10/blog-post_98.html' rel='bookmark' title='permanent link'><abbr class='published' itemprop='datePublished' title='2024-10-08T23:03:00-07:00'>23:03</abbr></a>
</span>
<span class='post-comment-link'>
</span>
<span class='post-icons'>
<span class='item-control blog-admin pid-1812462721'>
<a href='https://www.blogger.com/post-edit.g?blogID=2258801659978444105&postID=7585071633640158845&from=pencil' title='修改博文'>
<img alt='' class='icon-action' height='18' src='https://resources.blogblog.com/img/icon18_edit_allbkg.gif' width='18'/>
</a>
</span>
</span>
<div class='post-share-buttons goog-inline-block'>
<a class='goog-inline-block share-button sb-email' href='https://www.blogger.com/share-post.g?blogID=2258801659978444105&postID=7585071633640158845&target=email' target='_blank' title='通过电子邮件发送'><span class='share-button-link-text'>通过电子邮件发送</span></a><a class='goog-inline-block share-button sb-blog' href='https://www.blogger.com/share-post.g?blogID=2258801659978444105&postID=7585071633640158845&target=blog' onclick='window.open(this.href, "BlogThis!")
没有评论:
发表评论